近年生成AIが急速に普及する中、「ベクトルデータベース」への注目度が高まっています。
ベクトルデータベースは、テキストや画像、音声、動画などの非構造化データを扱う際、効率的なデータ処理を可能にする、”AI時代”において欠かせない技術です。
一方、ベクトルデータベースは難解な内容なので「聞いたことはあるけれど、よくわからない」という人も多いのではないしょうか。
そこで今回の記事では、ベクトルデータベースとは何か、仕組みや概要をわかりやすく解説していきます。さらにベクトルデータベースのメリットやデメリット、活用事例も合わせて紹介しています。
ベクトルデータベースについて、今一度理解を深めたいという方は、ぜひご一読ください!
ベクトルデータベースとは
ベクトルデータベースとは、テキストや画像・音声などの非構造化データや半構造化データを、「ベクトル」という数値の配列として扱い、データを保存・管理・検索するために利用されるデータベースのことです。
例え話で説明します。図書館で本を探すことを想像してみてください。
従来のデータベースでは、本を「タイトル」や「著者名」で検索するようなイメージです。対して、ベクトルデータベースは本の内容を分析し、「恋愛小説」「ミステリー」「子供向け」といった形で特徴を数値化して、多角的に似たような特徴を持つ本をまとめて検索できるようにします。ベクトルデータベースによって、より高度で効率的な検索や類似性の判定が可能になるのです。
従来型のデータベースでは、画像や映像、音声に対する高度な処理が難しいため、現代において、ベクトルデータベースは欠かせません。例えば、大きな注目を集めているChatGPTを始めとした生成AIも、ベクトルデータベースのおかげで膨大なデータを学習しつつ高速な回答の生成を可能にしています。
実はECサイトでも、検索ワードに対する類似の商品や、過去の購入歴から似た商品を提案するために、ベクトルデータベースが使用されています。最近では、工具通販の「モノタロウ」がベクトル検索を導入し、検索のヒット率を高めたというニュースがありました。
他にも、WebサイトのFAQシステムでも、類似のワードや過去の問い合わせなどからユーザのニーズに合わせた自動回答をするものもありますが、これはベクトルデータベースを用いているケースが多いです。
最近では、「画像検索」を使ってキーワードや名前を知らなくても画像を読み込ませることで、回答を得ることができますよね。これもまた、ベクトルデータベースが用いられている事例です。
このように、ベクトルデータベースは、従来のデータベースでは扱いにくかった画像や映像、音声などのデータを、その意味や特徴に基づいて検索することを可能にします。
ベクトルデータベースの仕組みについて
ベクトルデータベースの仕組みを、以下の3つのステップで簡単に説明します。
1.データのベクトル化
まず、テキストや画像、映像・音声などのデータを、「ベクトル」と呼ばれる数値のリストに変換します。これは、データの特徴を数値で表現するプロセスです。
2.ベクトルの格納
変換されたベクトルは、ベクトルデータベース内に格納されます。ベクトルデータベースは、これらのベクトルを効率的に保存・管理するための特別な仕組みを持っています。
3.類似検索
ユーザーが検索クエリを入力すると、クエリもベクトルに変換されます。そして、データベースに格納されているベクトルの中から、クエリベクトルに類似したベクトルを検索します。
ベクトル間の類似度は、ユークリッド距離やコサイン類似度などの指標で計算されます。ベクトルデータベースは、これらの仕組みによって、大量の非構造化データを効率的に処理し、高精度な類似検索を実現しています。
従来型データベースとの違い
それでは、従来型のデータベース(リレーショナルデータベース)とは、何が違うのでしょうか?
まず、従来のリレーショナルデータベースは、行と列を利用してデータを管理します。(ExcelやGoogleスプレッドシートのようなイメージです。)リレーショナルデータベースでは、行と列の表形式でデータが整然と管理されている状態です。そのため構造化されたデータの管理に向いています。検索する際は、検索の範囲指定やキーワード一致が必要です。
一方、ベクトルデータベースは、多次元空間のベクトルを利用してデータを管理します。ベクトルの距離や方向、角度などで類似の情報を把握することが可能です。そのため非構造化データ向けと言えます。ベクトルデータベースは、大まかなキーワードや画像を提示するだけで、類似の情報を得ることができます。
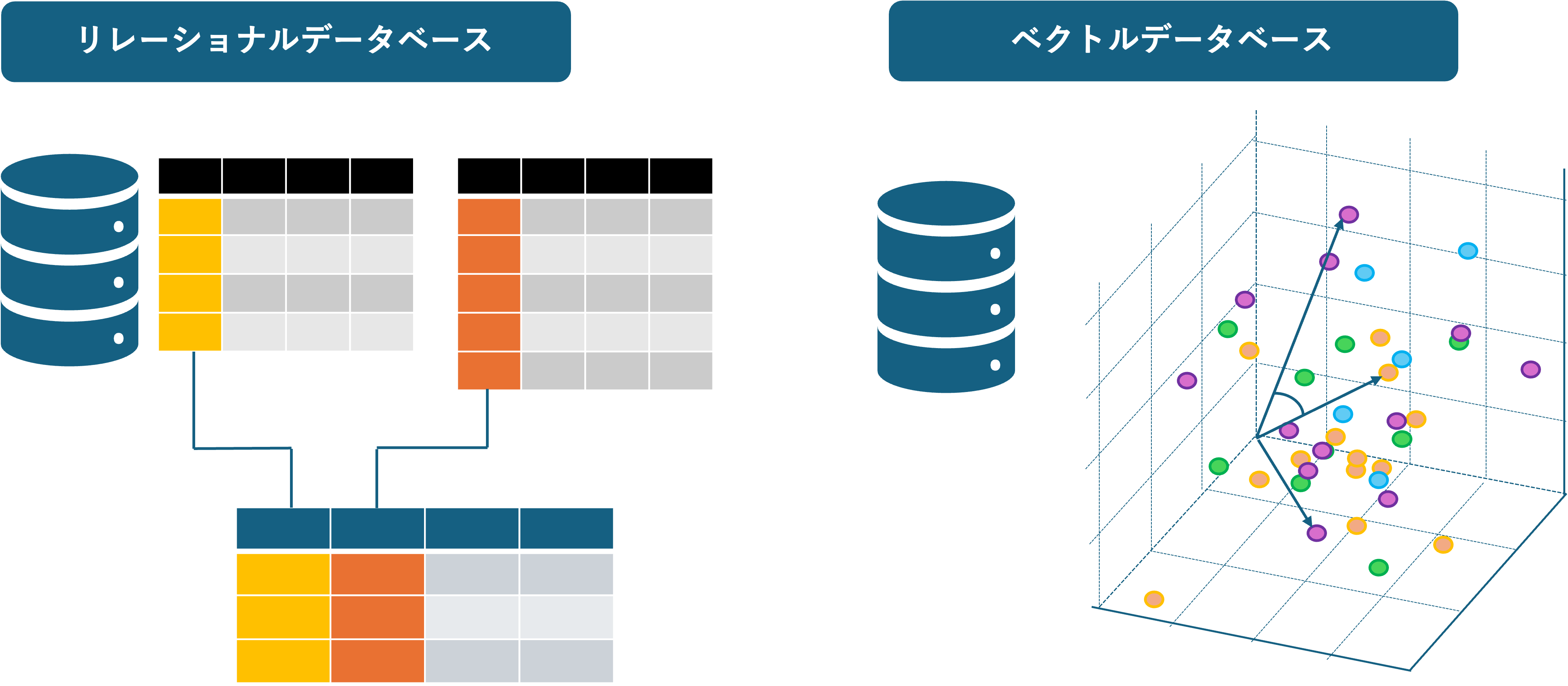
違いを以下の表にまとめました。
| リレーショナルデータベース | ベクトルデータベース | |
| 構造 | 行や列 | 多次元空間のベクトル |
| 向いているデータ | 構造化データ | 非構造化データ |
| 検索方法 | 検索ワードの一致 | 類似検索 |
| 用途 | 従来のデータ管理 | AIや機械学習 |
ベクトルデータベースのメリット
ベクトルデータベースのメリットは以下の通りです。
- 高速な類似検索を実現
- 柔軟なデータ処理が可能
- AI・機械学習との親和性
- RAGに欠かせない技術
それぞれ見ていきましょう。
高速な類似検索を実現
ベクトルデータベースは高次元ベクトル空間上でデータを扱うため、膨大なデータの中から迅速な類似検索が可能になります。
例えば、画像検索では、アップロードした画像データをもとに瞬時に検索結果を提案することが可能です。また、Amazonや楽天で買い物する時など、ユーザーの好みに合った商品を提案したり、購入する商品と合わせて購入されることが多い商品などを瞬時に紹介します。
さらに最近ではAIを利用して、文章の意味まで含めたコピー率を調べることも可能です。文章をAIに読み込ませることで、どこから引用されたものか盗作などを調べることができます。その他、顔認証、音声認識など、類似度の判定が重要なアプリケーションで威力を発揮します。
柔軟なデータ処理が可能
ベクトルデータベースは、非構造化データを柔軟に処理できます。
従来のデータベースは、文章や数字など構造化データを収容するのに優れていましたが、ベクトルデータベースは、画像や映像、音声といった非構造のデータ処理が可能になりました。これにより、従来は扱うことが難しかった多様なデータを活用できるようになり、新たなアプリケーションの可能性が広がりました。
例えば、AIコールセンターでは、顧客の質問(声)をベクトル化し、過去のFAQと照らし合わせながら自動で回答することが可能になります。また、IoTデバイスデータなどの新しい種類のデータ処理も可能になります。IoTセンサーから得られる温度、振動、位置情報などを利用して設備の状態の監視することで、異常パターンを感知することが可能です。これを利用し工場などでは、機械が故障することを事前に予測ができるようになります。
AI・機械学習との親和性
ベクトルデータベースは、機械学習やAIとの親和性が高いです。
AI・機械学習モデルは、多くの場合でデータをベクトルとして処理します。ベクトルデータベースでは、 ベクトルデータをネイティブに扱えるため、AI・機械学習モデルとの連携がスムーズなのです。
例えば、AIモデルが生成したベクトルをベクトルデータベースに格納し、類似検索や分析に利用することができます。また、ベクトルデータベースからデータを効率的に取得して、AIモデルの学習に利用することもできます。
RAGに欠かせない技術
ベクトルデータベースは、注目を集めているRetrieval Augmented Generation (RAG) に欠かせない技術です。RAGは、大規模言語モデル (LLM) が、外部の知識ソースから情報を取得して、より正確で詳細な回答を生成する手法です。
例えで説明すると、LLMは、たくさんの本を読んだ優秀な学生のようなものです。しかし、LLMが学習した情報は限られており、最新の情報や専門的な知識は不足している場合があります。そこで、RAGは、LLMに「図書館」を与えて、必要な時に必要な情報を学習できるようにするようなものです。図書館には、最新の論文、ニュース記事、社内文書など、様々な情報が蓄積されています。
近年、企業では社内のデータをLLMに読み込ませて自社データも理解したオリジナルのAIを構築する「RAG」が増えています。ベクトルデータベースは、RAGにおいてLLM が必要とする情報を効率的に検索するための基盤となります。
具体的には、LLMからのクエリをベクトル化し、ベクトルデータベースに格納されたドキュメントベクトルとの類似度を計算することで、関連性の高いドキュメントを検索します。これにより、LLMは最新の情報を取得し、より信頼性の高い回答を生成することができるのです。
関連記事 RAGとは?LLMの課題解決に導く生成AIの技術を解説
ベクトルデータベースの代表的なユースケース
ベクトルデータベースの概要やメリットは理解できましたでしょうか。
続いて、実際にどんなところで使われているのか詳しく見ていきましょう。ベクトルデータベースの代表的なユースケースには以下のようなものが挙げられます。
- レコメンドシステム
- 画像検索
- チャットボット
- 文章の類似度判定
- 不正検知
それぞれ見ていきましょう。
レコメンドシステム
顧客の嗜好に合った商品やサービスを推薦するレコメンドシステムでも、ベクトルデータベースは利用されます。
例えば、Amazon、Netflixなどのサービスのレコメンドシステムでは、顧客の購入歴や視聴履歴に合わせておすすめの商品や番組を提案する機能があります。オンラインショッピングをしている中で、「この商品を購入した人は以下のような商品も購入しています」といった文言を見たことがある人も多いでしょう。これはベクトルデータベースを利用し、瞬時にデータに基づき類似商品を提案しているのです。
画像検索
類似画像検索やGoogle画像検索など、画像検索にもベクトルデータベースが用いられています。
Google画像検索では、検索窓の横にカメラの表示マークがあり、スマホでスキャンするだけで画像の商品や類似の商品の情報を得ることを可能としています。Googleは、ディープラーニングなどの技術を用いて、画像の特徴を分析し、それをベクトルに変換しています。このベクトルは、画像の色、形、テクスチャなどの視覚的な特徴を数値で表現したものです。抽出されたベクトルは、Googleの持つ大規模なベクトルデータベースに格納されています。ユーザーが画像をアップロードすると、その画像も同様にベクトル化されます。そして、ベクトルデータベースに格納されている画像ベクトルの中から、アップロードされた画像のベクトルに類似したベクトルが検索されるのです。
チャットボット
ベクトルデータベースは、簡単な単語を入力すると、類似の情報を得ることができます。これは、チャットボットなどでの自然な会話を可能にします。
例えば、企業のカスタマーサービスなどでは、ロボットチャットが設置されています。ベクトルデータベースを利用し、過去の情報や基本情報を読み込ませることで、簡単な質問に答えることを可能にしているのです。企業独自の情報をベクトルデータベースに格納しているため、ここでは先ほど紹介したRAGも用いられています。
文章の類似度判定
ベクトルデータベースを利用すると、文章の類似度を判定し、盗作などを防止することが可能です。
類似度判定ではまず、文章をベクトルに変換(文章の意味や特徴を数値のリストで表現)します。変換されたベクトルは、ベクトルデータベースに格納されます。そして、2つの文章間のベクトルの距離や角度を計算し、類似度を判定します。
この際、コサイン類似度を用いることが多いです。コサイン類似度は、2つのベクトルの間の角度の余弦を計算し、1に近いほど類似度が高いことを示します。
ベクトルデータベースを用いることにより、単語の一致だけでなく、意味的な類似度などまで判定できるため、剽窃チェックに限らず検索エンジンやFAQシステムなど様々な場面で活用されています。
不正やミスの検知
ベクトルデータベースでは、正常データを学習させることで、異常を感知することも可能にします。
例えば、文章を入力するだけで、文法のミスや誤字などを瞬時にキャッチし、訂正案を表示できるのです。また工場などでは、機械が正常に稼働しているか確認するに、ベクトルデータベースは利用されます。正常なパターンとは異なる数値を検出すると、異常を予想し知らせることも可能です。
ベクトルデータベースの課題やデメリット
ここまで、ベクトルデータベースのメリットを中心に見てきました。一方で、ベクトルデータベースには以下のような課題やデメリットもあります。
- 高次元データの扱い
- スケーラビリティ
- 精度と速度のトレードオフ
それぞれ見ていきましょう。
高次元データの扱い
ベクトルデータは、数百から数千、時には数万次元になることもあり、高次元になるほどデータの処理が難しくなります。高次元データの処理には、以下のような課題があります。
次元の呪い
次元数が増えると距離が均一化し、類似性が正確に判定できなくなる場合があります。
計算コストの増加
大容量のデータを読み込むことで、次元数が増加します。するとベクトル演算の計算量が増加し、情報を処理したり、回答するのに時間を要する場合があります。
ストレージ容量の増加
高次元データは、従来のデータに比べて、学習するデータが多く、ストレージの容量をかなり消費してしまう恐れがあります。
これらの課題を解決するために、次元削減をしつつ、情報量のロスを抑えます。次元削減の代表的な方法は主成分分析と呼ばれ、複数の変数をいくつかの変数に合成する手法です。
スケーラビリティ
1度に収容されるデータの量が増えると、速度の原則などが懸念されます。そのためシステムを効率的に拡大する必要があります。
解決策として、1台のサーバーに依存させず、データを分散させることが必要です。FacebookのANNライブラリ「Faiss」やGoogle Cloudでの分散型データベース運用のように、分野環境で管理し、データ量に応じて拡張する方法などが挙げられます。またよく使われる検索結果などは、再利用し検索時間の短縮を計ります。
精度と速度のトレードオフ
ベクトルデータベースでは、スピードと精密さのバランスがとられています。高速な検索を実現するために、近似最近傍探索などのアルゴリズムが用いられますが、類似の情報を提供できる一方、厳密な検索とは異なる類似の結果のみを得ることになります。
解決方法としては、いくつかありますが、一例として検索を2段階方式で行う手法。全体を絞り込んだ後に、厳密な検索結果を出しより正確な回答を提示します。ユースケースに応じて、精度と速度のバランスを調整する必要があります。例えばECサイトでは、類似の商品を素早く、提案することが重要なため、速度を優先するなどです。
まとめ
ここまで、ベクトルデータベースについてさまざまな側面から解説してきました。ベクトルデータベースは、画像や映像など非構造化データまで管理することができ、さらに類似の情報を迅速に提示することが可能です。
ベクトルデータベースを詳しく理解することで、効率よく業務を進めたり、新たなアプリケーションの開発に役立つでしょう。AI時代において欠かせない技術であるため、この記事を参考に理解を進めてくださいね。